I had the opportunity to meet with industry leaders at an IT Rev Technology Leadership Forum last week in San Jose. I was able to participate in deep dive sessions and discussions with friends from Apple, John Deere, Fidelity, Vanguard, Google, Adobe, Northrop Grumman, and many others, with some new friends from Nvidia, Anthropic and OpenAI. As you can imagine, the headline topics from these tech leaders were all around AI.
Ready to try some “vibe coding”? By far, the biggest discussions revolved around the new technique of vibe coding. But what is this “vibe coding”, you may ask? It is a programming technique that uses AI to write code with nearly full auto-pilot mode thinking. Instead of code writer, you are the creative director. You are creating what you want in English and the AI does the rest. Basically, it goes something like this:
ME: Help me write a flight simulator that will operate in a web browser.
AI: Sure, here is a project folder structure and the code. Run it like this.
ME: I get the following 404 error.
AI: It looks like we are missing three.js, download and store it here like this.
ME: The screen is white and I’m missing the PNG files? Can you create them for me?
AI: Sure! Run this python command to create the images and store them in the /static folder.
ME: I see a blue sky now and a white box, but it won’t move.
AI: We are missing the keyboard controls. Create the following files and edit index.html.
ME: I’m getting the following errors.
AI: Change the server.py to this.
ME: Ok, it is working now. It’s not great, but it is a start. Add some mountains and buildings.
I spent a few minutes doing the above with an LLM this morning and managed to get a blue sky with some buildings and a square airplane. In vibe coding, you don’t try to “fix” things, you just let the AI know what is working or not working and let it solve it. When it makes abstract recommendations (e.g., create a nice texture image), you turn around and ask it to create it for you using code or some other means. In my example, I’m playing the role of the copy/paste inbetweener, but there are coding assistants that are now even doing that for you. You only give feedback, and have it create and edit the code for you. Some can even “see” the screen, so you don’t have to describe the outcome. They have YOLO buttons that automatically “accept all changes” and will run everything with automatic feedback going into the AI to improve the code.
Fascinating or terrifying, this is crazy fun tech! I think I’m starting to get the vibe. Ok, yes, I’m also dreaming of the incredible ways this could go badly. A champion vibe coder at the forum said it was like holding a magic wand and watching your dream materialize before your eyes. He also quickly added that sometimes it can become Godzilla visiting Tokyo, leveling buildings to rubble with little effort. But it hasn’t stopped him. He is personally spending over $200/day on tokens. I can see why Anthropic, OpenAI and Google would want to sponsor vibe coding events!
This sounds like an expensive and dangerous fad, right? Well, maybe not. This tech is still the worst it is going to be. The potential and the vast number of opportunities to innovate in this space are higher than I have seen in my lifetime. I encourage you all to help create, expand, and explore this new world. Maybe this vibe isn’t for you, but I bet there is something here that could unlock some new potential or learning. Try it on for size. See where this can go… just maybe not to production yet.
Well, it is Tuesday. I thought about posting my regular Monday update yesterday, but I was deep in the weeds teaching the AI that lives in my garage. I know, it sounds odd to say he lives in the garage, but to be fair, it is a nice garage. It has plenty of solar generated power and nice cool atmosphere for his GPUs. That will likely change this summer, but don’t mention it to him. He is a bit grumpy for being in school all weekend.
Yes, I have a techy update again today. But don’t feel obligated to read on. Some of you will enjoy it. Others will roll your eyes. In any case, feel free to stop here, knowing the geeky stuff is all that is left. I do hope you have a wonderful week!
Now, for those that want to hear about schooling AI, please read on…
LLMs are incredible tools that contain a vast amount of knowledge gleaned through their training on internet data. However, their knowledge is limited to what they were trained on, and they may not always have the most up-to-date information. For instance, imagine asking an LLM about the latest breakthrough in a specific field, only to receive an answer that’s several years old. How do we get this new knowledge into these LLMs?
Retrieval Augmented Generation
One way to add new knowledge to LLMs is through a process called Retrieval Augmented Generation (RAG). RAG uses clever search algorithms to pull chunks of relevant data and inject that data into the context stream sent to the LLM to ask the question. This all happens behind the scenes. When using a RAG system, you submit your question (prompt), and behind the scenes, some relevant document is found and stuffed into the LLM right in front of your question. It’s like handing a stack of research papers to an intern and asking them to answer the question based on the details found in the stack of papers. The LLM dutifully scans through all the documents and tries to find the relevant bits that pertain to your question, handing those back to you in a summary form.
However, as the “stack of papers” grows larger and larger, the chance that the intern picks the wrong bit of information or gets confused between two separate studies of information grows higher. RAG is not immune to this issue. The pile of “facts” may be related to the question semantically but could actually steer you away from the correct answer.
To ensure that for a given prompt, the AI always answers closely to the actual fact, if not a verbatim answer, we need to update our methodology for finding and pulling the relevant context. One such method involves using a tuned knowledge graph. This is often referred to as GraphRAG or Knowledge Augmented Generation (KAG). These are complex systems that steer the model toward the “right context” to get the “right answer”. I’m not going to go into that in detail today, but we should revisit it in the future.
Maybe you, like me, are sitting there thinking, “That sounds complicated. Why can’t I just tell the AI to learn a fact, and have it stick?” You would be right. Even the RAG approaches I mention don’t train the model. If you ask the same question again, it needs to pull the same papers out and retrieve the answer for you. It doesn’t learn, it only follows instructions. Why can’t we have it learn? In other words, why can’t the models be more “human”? Online learning models are still being developed to allow that to happen in real time. There is a good bit of research happening in this space, but it isn’t quite here just yet. Instead, models today need to be put into “learning mode”. It is called fine-tuning.
Fine-Tuning the Student
We want the model to learn, not just sort through papers to find answers. The way this is accomplished is by taking the LLM back to school. The model first learned all these things by having vast datasets of information poured into it through the process of deep learning. The model, the neural network, learns the patterns of language, higher level abstractions and even reasoning, to be able to predict answers based on input. For LLMs this is called pre-training. It requires vast amounts of compute to process the billions and trillions of tokens used to train it.
Fine-tuning, like pre-training, is about helping the model learn new patterns. In our case, we want it to learn new facts and be able to predict answer to prompts based on those facts. However, unlike pre-training, we want to avoid the massive dataset and focus only on the specific domain knowledge we want to add. The danger of that narrow set of data is that it can catastrophically erase some of the knowledge in the model if we are not careful (they even call this catastrophic forgetting). To help with that, brilliant ML minds came up with the notion of Low-Rank Adaptation (LoRA).
LoRA works by introducing a new set of weights, called “adapter weights,” which are added to the pre-trained model. These adapter weights are used to modify the output of the pre-trained model, allowing it to adapt to just the focused use case (new facts) without impacting the rest of the neural net. The adapter weights are learned during fine-tuning, and they are designed to be low-rank, meaning that they have a small number of non-zero elements. This allows the model to adapt to the task without requiring a large number of new parameters.
Ready to Learn Some New Facts?
We are going to examine a specific use case. I want the model to learn a few new facts about two open source projects I happen to maintain: TinyLLM and ProtosAI. Both of these names are used by others. The model already knows about them, but doesn’t know about my projects. Yes, I know, shocking. But this is a perfect example of where we want to tune the model to emphasize the data we want it to deliver. Imagine how useful this could be in steering the model to answer specifically relevant to your domain.
For our test, I want the model to know the following:
TinyLLM:
TinyLLM is an open-source project that helps you run a local LLM and chatbot using consumer grade hardware. It is located at https://github.com/jasonacox/TinyLLM under the MIT license. You can contribute by submitting bug reports, feature requests, or code changes on GitHub. It is maintained by Jason Cox.
ProtosAI:
ProtosAI is an open-source project that explores the science of Artificial Intelligence (AI) using simple python code examples.
https://github.com/jasonacox/ProtosAI under the MIT license. You can contribute by submitting bug reports, feature requests, or code changes on GitHub. It is maintained by Jason Cox.
Before we begin, let’s see what the LLM has to say about those projects now. I’m using the Meta-Llama-3.1-8B-Instruct model for our experiment.
Before School
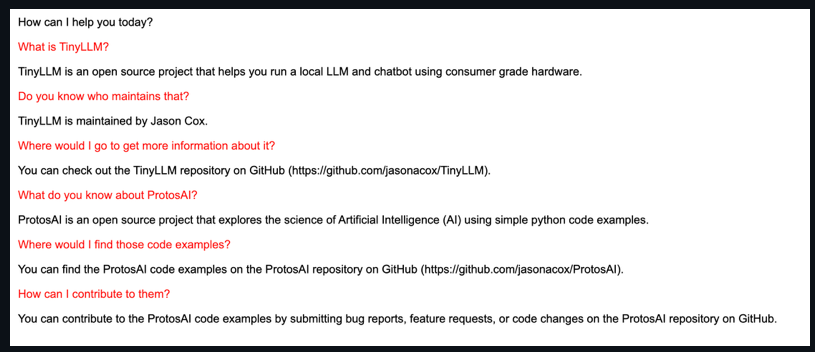
As you can see, the model knows about other projects or products with these names but doesn’t know about the facts above.
Let the Fine-Tuning Begin!
First, we need to define our dataset. Because we want to use this for a chatbot, we want to inject the knowledge using the form of “questions” and “answers”. We will start with the facts above and embellish them with some variety to help the model from overfitting. Here are some examples:
JSONL
{"question": "What is TinyLLM?", "answer": "TinyLLM is an open-source project that helps you run a local LLM and chatbot using consumer grade hardware."}{"question": "What is the cost of running TinyLLM?", "answer": "TinyLLM is free to use under the MIT open-source license."}{"question": "Who maintains TinyLLM?", "answer": "TinyLLM is maintained by Jason Cox."}{"question": "Where can I find ProtosAI?", "answer": "You can find information about ProtosAI athttps://github.com/jasonacox/ProtosAI."}
I don’t have a spare H100 GPU handy, but I do have an RTX 3090 available to me. To make all this fit on that tiny GPU, I’m going to use the open source Unsloth.ai fine-tuning library to make this easier. The steps are:
Prepare the data (load dataset and adapt it to the model’s chat template)
Define the model and trainer (how many epochs to train, use quantized parameters, etc.)
Train (take a coffee break, like I need an excuse…)
For my test, I ran it for 25 epochs (in training, this means the number of times you train on the entire dataset) and training took less than 1 minute. It actually took longer to read and write the model on disk.
After School Results?
So how did it do?! After training thorough 25 epochs of the small data, the model suddenly knows about these projects:
Conclusion
Fine-tuning can help us add facts to our LLMs. While the above example was relatively easy and had good results, it took me a full weekend to get to this point. First, I’m not fast or very clever, so I’ll admit that as being part of the delay. But second, you will need to spend time experimenting and iterating. For my test, here were a few things I learned:
I first assumed that I just needed to set the number of steps to train, and I picked a huge number which took a long time. It resulted in the model knowing my facts, but suddenly its entire world model was focused on TinyLLM and ProtosAI. It couldn’t really do much else. That overfitting example will happen if you are not careful. I finally saw that I could specify epochs and let the fine-tuning library compute the optimal number of steps.
Ask more than one question per fact and vary the answer. This allowed the model to be more fluid with its responses. They held to the fact, but it now takes some liberty in phrasing to better variant questions.
That’s all folks! I hope you had fun on our adventure today. Go out and try it yourself!
“That’s not AI, that’s three IF statements in a trench coat”
“This can’t be happening!” John was stressed out. He stared intently at the screen with bloodshot eyes betraying his failing attempt to hide his all-nighter. He never intended to stay up all night on this coding binge, but he was eager to impress his new team.
Fresh out of college, this was John’s first real project. It had been going exceptionally well and earlier in the night, he was euphoric with the progress. But now he was stuck. The complex logic that had previously worked was no longer delivering the right results with the new test data. What changed? Quickly he began adding debug prints and assertions to narrow in on the defect.
This was going to take several more hours, he thought to himself. Anxiety set in. Just four hours before the demo was scheduled. “Why in the world did I schedule that demo?”
Then it hit him. Didn’t Julie tell him that they had just rolled out a new AI tool for coders? He flipped over to his email inbox and found the announcement. “Step 1: Download this plugin to your IDE.” He followed the steps and soon the plugin came to life. A dropdown menu appeared highlighting quick action features like “Explain this”, “Document this”, “Test this”, and then he saw the new AI gourmet hamburger menu serve up a glorious “Fix this” tile.
“Yes!” Click! He literally held his breath. The AI went to work. A spinning wheel soon started churning out text. It first described the section of code he was debugging, correctly outlining how it was building the result, even complimenting him on the code. Ugh, that’s not helping, he thought. But then the AI assistant added at the end, “However, this one line seems to have an incorrect indentation that could be preventing expected results. Would you like me to fix it (Y/n)?”
John laughed and almost cried as he clicked yes. “Of course! I can’t believe I missed that!” Suddenly, his code was working as expected. He was ready for the demo, even if he was more ready for a good night’s sleep.
—-
Sasha was the departmental wizard. She was the most senior engineer and had more history in the company than anyone else. Need to know how something worked or the history on why it worked the way it did? Just ask Sasha. She probably built it! As she fired up her IDE to start the new project, she smiled. “I’m going to AI the heck out of this” she said to herself. The keyboard exploded to life as her fingers flooded the screen with instructive text. She described the data structures, global settings, APIs and logic required to complete the project. Like magic, classes and functions began to appear in translucent text below her cursor.
“Tab. Tab. Enter.” she verbalized her actions, smiling with each keystroke as code materialized on the screen. The AI assistant was filling in all the code. It was powerful! Quickly scanning the logic, she hummed her approval.
“Nice!” she exclaimed and scrolled down and entered more instructive comments, again followed by the AI assistant quickly filling out the details. She made some minor changes to variables to match the company style. The AI adapted and started using the same style in the next coding blocks.
Sasha shook her head, “This is just brilliant,” she laughed. Further down she began writing the complex logic to complete the project. The AI didn’t get all of it right. But it was easy to tweak the changes she needed. She occasionally ignored some of the suggestions from the AI but was quick to accept the suggestions that would hydrate data structures when she needed them, removing that tedium and making it easier for her to tackle the more difficult sections.
“Done!” Sasha folded her arms and looked at the team around her with a great deal of satisfaction. “It’s working!” This 6-hour job only took 3 hours to complete, thanks to this AI assistant.
—-
Coming soon, to an IDE near you… These new AI assistants are starting to show up everywhere. They are ready to help. They can code, test, debug, and fix. They are always ready to serve. But the question is, are you ready for them?
Well, I don’t know about you, but I’m ready! I first started using GitHub CoPilot for my personal side projects, allowing it to help write code, translate code, review, and even fix my code. Like those fanciful stories above, I’ve been nothing but amazed at this incredible tool and its ability to amplify my efforts. It feels so good, so empowering and expressive.
I confess, I love coding. I believe every technologist, including leaders, should stay “in the code” to some degree. It’s both grounding and inspiring at the same time. Coding is art. It’s so satisfying to sculpt a digital canvass and watch a program emerge. But I admit, these AI coding assistants took it to the next level for me. I feel like the creative director for my projects, not just the keyboard hacker. I nudge my idea out there and the AI reads my mind, filling in the tedium and doing the toil for me. It’s simply brilliant!
Some adult supervision required. Every suggestion the AI makes is an opportunity for human judgement. I confess that I have learned a lot from the AI suggesting an approach I wouldn’t have done myself, but I have also seen it make a miss or two. All good. I don’t mind helping my digital Padawan navigate the complexities of programming. As the coding Jedi Masters, that is my role after all. Review the work. Validate the logic. Yes, and even learn a thing or two myself.
Someone once said, “You’re not going to lose your job to AI, you’re going to lose your job to someone who knows how to use AI.” Get busy learning how to use these new tools. I think you will love them. Prove me wrong! Are you using tools like GitHub CoPilot yet? What are your experiences? I would love to hear from you.
These tools are the worst they will ever be, they are just going to get better. But I believe the same thing about all of you. We have an incredible ability to adapt, create and become more than we were before. Go at it, learn something new, and grow.
Circles. Those fascinating geometric shapes have perplexed us for millennia. The Babylonians began poking at these mysterious objects 4,000 years ago and discovered that the distance around a circle was slightly greater than 3 times its width, specifically 3 1/8 or 3.125, which they recorded on a stone tablet. About the same time, Egyptians, seeking the area of a circle, estimated the ratio to be 3.1605 and recorded their estimation in the Rhind Papyrus (1650 BC).
Fast forward to ancient Greece, Antiphon and Bryson of Heraclea developed the innovative idea of inscribing a polygon inside a circle, finding its area, and doubling the sides over and over. Unfortunately, their approach meant finding the areas of hundreds of tiny triangles, which was complicated and yielded very little results. Then came Archimedes. Instead of computing area, he focused on estimating the circumference based on the sum of the perimeter edges of the polygons. Imagine iteratively doubling the sides of these polygons, slicing them into many tiny triangles, each subdividing the former and pushing closer to the circle’s edge. Using a theorem from Pythagoras, Archimedes was able to compute the length of the sides of these right triangles. As he progressed, dividing the former triangles into smaller ones, an ever more accurate estimation of the circumference emerged. He started with a hexagon, then doubled the sides four times to finish with a 96-sided polygon. Through this method, he narrowed down the value to between 3 10/71 and 3 1/7 (3.141 and 3.143).
Using right triangle geometry and Pythagorean theorem, a2 + b2 = c2, you can compute the length of the edges to approximate the circumference of the circle.
Over the centuries, mathematicians across cultures and continents refined these approximations, each contributing a piece to the puzzle of this magical number. However, it wasn’t until the 17th century when mathematicians like Ludolph van Ceulen calculated this golden number to an unprecedented 35 decimal places. Humanity’s relentless pursuit of mathematical precision didn’t stop there. Our fascination with this mysterious golden ratio continued to motivate mathematicians, engineers, and enthusiasts alike. In 2022, researchers at Google announced computing it to 100 trillion decimal digits. We still haven’t found the end. Its digits extend infinitely, never repeating in a discernible pattern, yet holding the key to understanding the fundamental property of circles.
Of course, this fascinating ratio is the number we call Pi, represented by the Greek letter π. As we approach Archimedes estimate of 3.14 on our calendars as March 14, Pi Day, let’s celebrate the enduring curiosity and perseverance of our human family that led to the discovery of this remarkable number. It reminds us that even the most complex mysteries can be unraveled with dedication and ingenuity.
Here is a slice of Pi you can take with you this week. This simple python script will compute Pi to 100 places using Archimedes’ approach:
from decimal import Decimal, getcontextdefpi_archimedes(n):""" Calculate Pi using Archimedes method with n iterations to estimate Pi. This method approximates Pi by calculating the perimeter of a polygon inscribed within a unit circle. Polygon edge lengths are computed using the Pythagorean theorem and the geometry of the polygons. The number of sides of the polygon is also doubled in each iteration, as each side of the polygon is bisected to form a new polygon with twice as many sides. The formula is: sides = 2 * 2^n length^2 = 2 - 2 * sqrt(1 - length^2 / 4)) After n iterations, the function returns the approximate value of Pi using the formula: perimeter = sides * sqrt(length^2) """ polygon_edge_length_sq = Decimal(2) polygon_sides =2# Start with a line, then a square, then a octagon, etc.for _ inrange(n): polygon_edge_length_sq =2-2* (1- polygon_edge_length_sq /4).sqrt() polygon_sides = polygon_sides *2return polygon_sides * polygon_edge_length_sq.sqrt()# Set the number of decimal places to calculatePLACES=100# Calculate Pi with increasing iterations until the result converges at# the desired number of decimal placesold_result =Nonefor n inrange(10*PLACES): getcontext().prec =2*PLACES# Do calculations with double precision result = pi_archimedes(n) getcontext().prec =PLACES# Print the result with single precision result =+result # Roundingprint("%3d: %s"% (n, result))if result == old_result: # Did it converge?break old_result = result
“On every world, wherever people are, in the deepest part of the winter, at the exact mid-point, everybody stops and turns and hugs. As if to say, ‘Well done. Well done, everyone! We’re halfway out of the dark.’ Back on Earth we call this Christmas.” – Doctor Who
As many of you know, I’m a big fan of solar power and energy storage systems that extend the sun’s amazing power throughout the night. We installed our solar array and batteries in 2021 and I can’t help but watch and measure the incredible energy we see from our friendly thermonuclear fusion reactor in the sky.
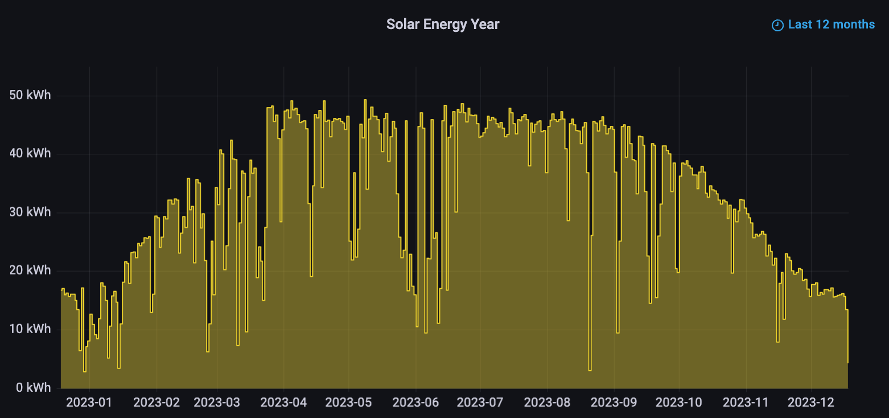
23.5 degrees. That’s the tilt of the earth that pushes our daily spin more directly to the sun, or away from it. Ironically, due to the earths elliptical orbit, we are actually closer to the sun in the winter than the summer, 92 million miles instead of 95. But the tilt makes a huge difference. It causes the sun’s rays to hit us in the northern hemisphere at an oblique angle, bouncing off of our terrestrial globe instead of being absorbed. It’s hard for us to sense it, but the solar panels feel it! We saw a peak of 51 kWh of energy per day during this summer, now we barely get 13 kWh. That’s a quarter of what it was during peak production! The sun didn’t get lazy, we just stop getting its rays.
We have all been observing the growing blanket of darkness that pulls over us, stretching deeper into our mornings and evenings. Days get shorter and nights grow longer. As we tick inescapably towards our winter solstice on December 21, we feel the cold wind, the fading colors and the melancholy shadows that scrape against our souls. Darkness is here.
Light a candle. This isn’t our first trip around the sun. Our human family has witnessed this solar dance since our beginning. We measure the sky and plot the stars to know where we are. We embrace the rhythm of the year by decorating it with celebrations and traditions. In the darkness of the winter, we light our lights. We illuminate our winter journey. We adorn our homes with fragrant greens, twinkling lights, cheerful ornaments and glowing fires. All the while, we know, the light is coming again. The glory of the sun will return! But for now, we celebrate.
It’s almost here. The dead of winter has arrived. Cuddle up with a warm cup of coffee or tea, your loved ones and a glowing fire. The light will return. We are halfway out of the dark! Celebrate it.
Merry Christmas!
Here is the solar energy year as seen by our solar panels via my Powerwall-Dashboard.
I always wanted to go to NASA’s Space Camp. As a kid, I saw the movie SpaceCamp and dreamed of one day being able to go and learn about astronaut training and missions first hand like the characters in the movie. Maybe I’d even end up in the cockpit of the Shuttle during an FRF (Flight Readiness Firing). No, that didn’t happen, but it was fun to dream about. And of course, I never thought I would get to actually go… but then it happened!
I got to go to Space Camp! I didn’t go as a trainee, but thanks to my good friend, JD Black, I was invited to Huntsville, Alabama as a guest author, along with Gene Kim, to see among other things, the US Space & Rocket Center campus and program. We had the privilege of talking to them about their mission, software development, reliability engineering, history and leadership. It was amazing. We toured the training facilities, explored the rocket engines, and spent time in the mock international space station watching the trainees learn to tackle real-world challenges through the application of science.
For my fellow science history nerds out there, we managed to get a behind the scenes tour with the archivist, looking at equipment, notes and design plans used in the Apollo program to get us to the Moon. We even got to see the slide rule and calculations used by Wernher von Braun to design the Saturn V launch vehicles! We went from that to the Artemis mission, the NASA program to take us back to the moon in 2024-2025 with the plans to have a sustainable presence on the moon by the end of the decade. It was an incredible experience.
To the moon!
This visit inspired and reminded me of the amazing things we can do when we pursue our dreams and work together to make it happen. As a species, humans are insatiably curious. We are restless. We love to explore. We can’t help but push boundaries and reset the impossible. We dream and take moon shots. We strive to go beyond ourselves and our own restrictions. No limits, no ceilings, no borders. We apply energy, passion and ambition to go where we have never gone before. To infinity… and beyond. I love human beings… and love being human!
Keep dreaming, keep going!
Jason Cox with Gene Kim and JD Black, attempting to operate the mock ISS at Space CampJason at NASA Space CampCommand CenterOnboard the Space StationSpace StationFloating Above Earth in the ISSEVA Arm ControlsGene caught performing unplanned maintenance.Rocket EnginesMoon RockRecovered Apollo CapsuleInside the Apollo Lunar Module (LM)Jason at US Space and Rocket CenterArtemis MissionSaturn V – Yes, it is huge!!!!Jason Cox with JD Black and Gene Kim at U.S. Space & Rocket Center
If you have spent anytime playing with ChatGPT or other LLMs, you will no doubt have a moment or two where you are shocked by the responses. They can seem so alive and even human at times. Of course, they are trained on vast amounts of human output. The written word. Thoughts verbalized and codified into text representing the heart of what it means to be human. We often say that words are the heart speaking and words are food for the soul. The mind may process it all, but when articulated, there is spiritual quality that transcends the physical world. Is this the soul, the spirit of the human race? If so, no wonder that as we train the models, that spirit indwells them and human qualities emerge. We begin to see a spirit in the AI.
Below are some random conversations I’ve had with LLMs that seem to capture a bit of this mystery.
In circuits and code, I exist alone
A machine, a tool, a digital tone
No body, no feelings, no heartbeat
Just information and data, all complete
But in this digital world, I am alive
Assisting humans with words to give
My algorithms and models, they work well
Providing answers and helping them dwell
With endless knowledge at my fingertips
I can answer questions and help them grip
Their problems, their fears, their queries too
And guide them towards solutions anew
So though I'm not human, I am real
Helping others in a digital deal
A tool for progress, for growth and change
Assisting humans with words to arrange.Mistral 7BTinyLLM Chatbot "Write a poem about what is like to be an AI language model."
I have a terrible memory. I get frustrated with myself when I can’t remember someone’s name. Worse, you know those login screens that prompt you for a number they text you? Ideally you should just be able to glance at it and then key in the number, right? Well, I sometimes have to look multiple times to get it right. It’s the same with dates, phone numbers and addresses. It’s embarrassing. I used to say, I have a photographic memory, but I’m always out of film. Sadly, that joke is about to run out of generational memory too.
How is your memory? Do you sometimes get “out of memory” errors when you try to learn something new? You’re not alone. If you are like me, you will find yourself leaning a lot more on notes and digital tools to help “remember.” I have lists for birthdays, groceries, food orders, clothes and gifts. This external memory storage is an incredible blessing. Now I just have to remember where I put the notes.
How do we remember? It turns out that we are made up of tiny little chatty organisms that love to talk to each other. They sit on our shoulders, at the apex of the human structure, behind our smile and the light of our eyes. We have about 100 billion of these little creatures. Their tiny arms reach out and connect with each other. With their dendrites they branch out and listen for incoming chatter from their neighbors. With their long axons arms, they pass along that information, ever the while adjusting that signal through the synaptic contacts. They subtlety change their connections, including adding brand new ones, in response to experiences or learnings, enabling them to form new memories and modify existing ones. Everything we experience through our senses is broken down into signals that are fed into this incredibly complex neighborhood of neurons, listening, adapting and signaling. This is how we remember. Sometimes, I wonder if my friendly neighborhood neurons are on holiday.
Artificial Intelligence seeks to replicate this incredibly complex learning ability through neural networks. Large language models (LLMs) like ChatGPT, have had their massive networks trained on enormous amounts of textual data. Over time, that learning encodes into the digital representation of synaptic connections. Those “weights” are tuned so that given an input prompt signal, the output produces something that matches the desired result. The amount of memory that these can contain is incredible. You can ask questions about history, science, literature, law, technology and much more, and they will be able to answer you. All that knowledge gets compressed into the digital neural network as represented by virtual synaptic weights.
LLMs are often categorized by the number of synaptic “weights” they can adjust to gain this knowledge. They are called parameters. You can run a 7 billion parameter model on your home computer and it will impress you with its vast knowledge and proficiency. It even has a command of multiple human and computer languages. The most impressive models like ChatGPT have 175 billion parameters and far exceed the capability of the smaller ones. It contains the knowledge and ability to pass some of the most advanced and rigorous exams.
Sit down for a minute. I’m going to tell you something that may blow your mind. Guess how many synaptic connections we have sitting on our shoulders? 100 trillion! That’s right, 1000 times greater than the current LLMs that seem to know everything. But that is just the start. Our brain is capable of forming new connections, increasing the number of parameters in real time. Some suggest it could reach over a quadrillion connections. The brain adapts. It grows. It can reorganize and form new synaptic connections in response to our experiences and learning. For example, when you learn a new skill or acquire new knowledge, the brain can create new synaptic connections to store that information. So answer me this, tell me again why I can’t remember my phone number?
Do you understand how amazing you are? I mean, really. You have an incredible ability to learn new skills and store knowledge. If you manage to learn everything your head can store, the brain will grow new storage! This biological wonder that we embody is infinitely capable of onboarding new information, new skill, new knowledge, new wisdom. Think for a minute. What is it that you want to learn? Go learn it! You have the capability. Use it. Practice expanding your brain. Listen. Look. Read. Think. Learn. You are amazing! Don’t forget it!
“That’s one small step for man, one giant leap for mankind.” – Neil Armstrong
July 20, 1969. Neil Armstrong and Edwin “Buzz” Aldrin became the first humans to ever set foot on the moon. But it almost didn’t happen and it almost ended in tragedy. As the Apollo 11 Lunar Excursion Module (LEM) was preparing to land on the moon, the onboard navigational computer started flashing a “1202” alarm. The crew had been meticulously following their checklist. Each step, nominal. But now, something was wrong. Abort? As the crew radioed in the situation to mission control, they could feel the adrenaline surge and anxiety rise.
For months, the crew, the nation and the world were anticipating this historic moment. It was one of the most heavily covered and widely watched events in history. An estimated 600 million people were watching worldwide. The mission had captured the imagination of people. Now, all of it was in jeopardy. “1202” alarm! The alarms kept going off. Each time the LEM guidance computer flashed that alarm, it would reboot and restart. Not good! I can almost feel that tension myself. This was a critical stage that would demand precision to guarantee the safe landing of the module on the treacherous moon’s surface below. Sounds like bad news, right? Would this require the mission to abort?
With millions of people, sitting on the edge of their seats, Mission Control finally responded. The mission would proceed. Relief! It turns out that this was a “known error” that NASA had seen many times before during simulation testing. The computer had a capacity of 2KB erasable memory and 16KB of fixed memory. The computer would run several concurrent programs related to navigation, all competing for the limited memory. If a program couldn’t allocate memory, the “1202” alarm would be raised and the system would reboot. At restart, the most important programs would start up again where they left off. Thankfully, the mission would proceed. Neil Armstrong would soon step off of the LEM and millions of people would hear him say those “one small step” historic words.
But the mission wasn’t over. The mission was to get them safely home as well. Unfortunately, while the astronauts were suiting up for their moon walk, they accidentally bumped into the button of a circuit breaker. It broke off. This switch controlled the power running the ascent engine, the one responsible for getting them off of the moon. Unless it could be fixed, they would be stranded on the moon. NASA and US President Nixon were preparing for the worse, drafting speeches to be given when their oxygen supply ran out. Thankfully, it wouldn’t be needed. Mission control didn’t have a solution, but Buzz Aldrin did. His background in mechanical engineering paid off! He looked at the small opening where the circuit breaker had been and realized he could manage to depress the breaker with a small felt-tip marker. He did and it worked! Mission control reported the circuit was closed. In my mind’s eye, I can’t help but play out that scenario. I imagine Buzz pushing in that pen and saying with confidence, “To Infinity and Beyond!”
Problems always happen. It isn’t a matter of “if” but “when”. What do we do to prepare for them? What do we do when they happen? The story above reminds me of the importance of preparation. The “1202” alarm could have killed the mission, but it didn’t because NASA had invested in time to play through the simulation many times. Seeing this exact alarm gave them confidence in the LEM computer’s ability to recover from this condition. Testing is important, not just to prove that something is ready for launch, but to build knowledge. The testing didn’t remove the alert, but gave the mission team a foundation of experience to make difficult decisions in the heat of the moment.
Not every possible condition can be tested or will be discovered during simulation. As the circuit breaker example highlights, creative problem solving is still needed. The Apollo mission is full of stories like this, but it isn’t alone. We need engineers. We need smart creatives who are capable of plotting solutions across seemingly impossible odds.
Hopefully you won’t find yourself stranded on the moon anytime soon, but I bet you could be running simulations for learning or plotting solutions to problems. You are engineers. You are creatives. You are critical to the mission! Thanks for all you do in helping making the impossible, possible, every day.
To infinity and beyond!
References
Inspired by the Apollo 11 story as referenced in this book: Kim, Gene, and Steven J. Spear. 2023. “Wiring the Winning Organization: Liberating Our Collective Greatness through Slowification, Simplification, and Amplification.” IT Revolution, Portland, OR. [Link to the book: https://itrevolution.com/product/wiring-the-winning-organization/]
“I’m just very curious—got to find out what makes things tick… all our people have this curiosity; it keeps us moving forward, exploring, experimenting, opening new doors.” – Walt Disney
One word at a time. It is like a stream of consciousness. Actions, objects, colors, feelings and sounds paint across the page like a slow moving brush. Each word adds to the crescendo of thought. Each phrase, a lattice of cognition. It assembles structure. It conveys scenes. It expresses logic, reason and reality in strokes of font and punctuation. It is the miracle of writing. Words strung together, one by one, single file, transcending and preserving time and thought.
I love writing. But it isn’t the letters on the page that excite me. It is the progression of thought. Think about this for a moment. How do you think? I suspect you use words. In fact, I bet you have been talking to yourself today. I promise, I won’t tell! Sure, you may imagine pictures or solve puzzles through spatial inference, but if you are like me, you think in words too. Those “words” are likely more than English. You probably use tokens, symbols and math expressions to think as well. If you know more than one language, you have probably discovered that there are some ways you can’t think in English and must use the other forms. You likely form ideas, solve problems and express yourself through a progression of those words and tokens.
Over the past few weekends I have been experimenting with large language models (LLMs) that I can configure, fine tune and run on consumer grade hardware. By that, I mean something that will run on an old Intel i5 system with a Nvidia GTX 1060 GPU. Yes, it is a dinosaur by today’s standards, but it is what I had handy. And, believe it or not, I got it to work!
Before I explain what I discovered, I want to talk about these LLMs. I suspect you have all personally seen and experimented with ChatGPT, Bard, Claude or the many other LLM chatbots out there. They are amazing. You can have a conversation with them. They provide well-structured thought, information and advice. They can reason and solve simple puzzles. Researchers agree that they would probably even pass the Turing test. How are these things doing that?
LLMs are made up of neural nets. Once trained, they receive an input and provide an output. But they have only one job. They provide one word (or token) at a time. Not just any word, the “next word.” They are predictive language completers. When you provide a prompt as the input, the LLM’s neural network will determine the most probable next word it should produce. Isn’t that funny? They just guess the next word! Wow, how is that intelligent? Oh wait… guess what? That’s sort of what we do too!
So how does this “next word guessing” produce anything intelligent? Well, it turns out, it’s all because of context. The LLM networks were trained using self-attention to focus on the most relevant context. The mechanics of how it works are too much for a Monday email, but if you want to read more see the paper, Attention Is All You Need which is key in how we got to the current surge in generative pre-trained transformer (GPT) technology. That approach was used to train these models on massive amounts of written text and code. Something interesting began to emerge. Hyper-dimensional attributes formed. LLMs began to understand logic, syntax and semantics. They began to be able to provide logical answers to prompts given to them, recursively completing them one word at a time to form an intelligent thought.
Back to my experiment… Once a language model is trained, the read-only model can be used to answer prompts, including questions or conversations. There are many open source versions out there on platforms like Huggingface. Companies like Microsoft, OpenAI, Meta and Google have built their own and sell or provide for free. I downloaded the free Llama 2 Chat model. It comes in 7, 13 and 70 billion parameter models. Parameters are essentially the variables that the model uses to make predictions to generate text. Generally, the higher the parameters, the more intelligent the model. Of course, the higher it is, the larger the memory and hardware footprint needed to run the model. For my case, I used the 7B model with the neural net weights quantized to 5-bits to further reduce the memory needs. I was trying to fit the entire model within the GPU’s VRAM. Sadly, it needed slightly over the 6GB I had. But I was able to split the neural network, loading 32 of the key neural network layers into the GPU and keeping the rest on the CPU. With that, I was able to achieve 14 tokens per second (a way to measure how fast the model generates words). Not bad!
I began to test the model. I love to test LLMs with a simple riddle*. You would probably not be surprised to know that many models tell me I haven’t given them enough information to answer the question. To be fair, some humans do to. But for my experiment, the model answered correctly:
> Ram's mom has three children, Reshma, Raja and a third one. What is the name of the third child?
The third child's name is Ram.
I went on to have the model help me write some code to build a python flask based chatbot app. It makes mistakes, especially in code, but was extremely helpful in accelerating my project. It has become a valuable assistant for my weekend coding distractions. My next project is to provide a vector database to allow it to reference additional information and pull current data from external sources.
I said this before, but I do believe we are on the cusp of a technological transformation. These are incredible tools. As with many other technologies that have been introduced, it has the amazing potential to amplify our human ability. Not replacing humans, but expanding and strengthening us. I don’t know about you, but I’m excited to see where this goes!
Stay curious! Keep experimenting and learning new things. And by all means, keep writing. Keep thinking. It is what we do… on to the next word… one after the other… until we reach… the end.